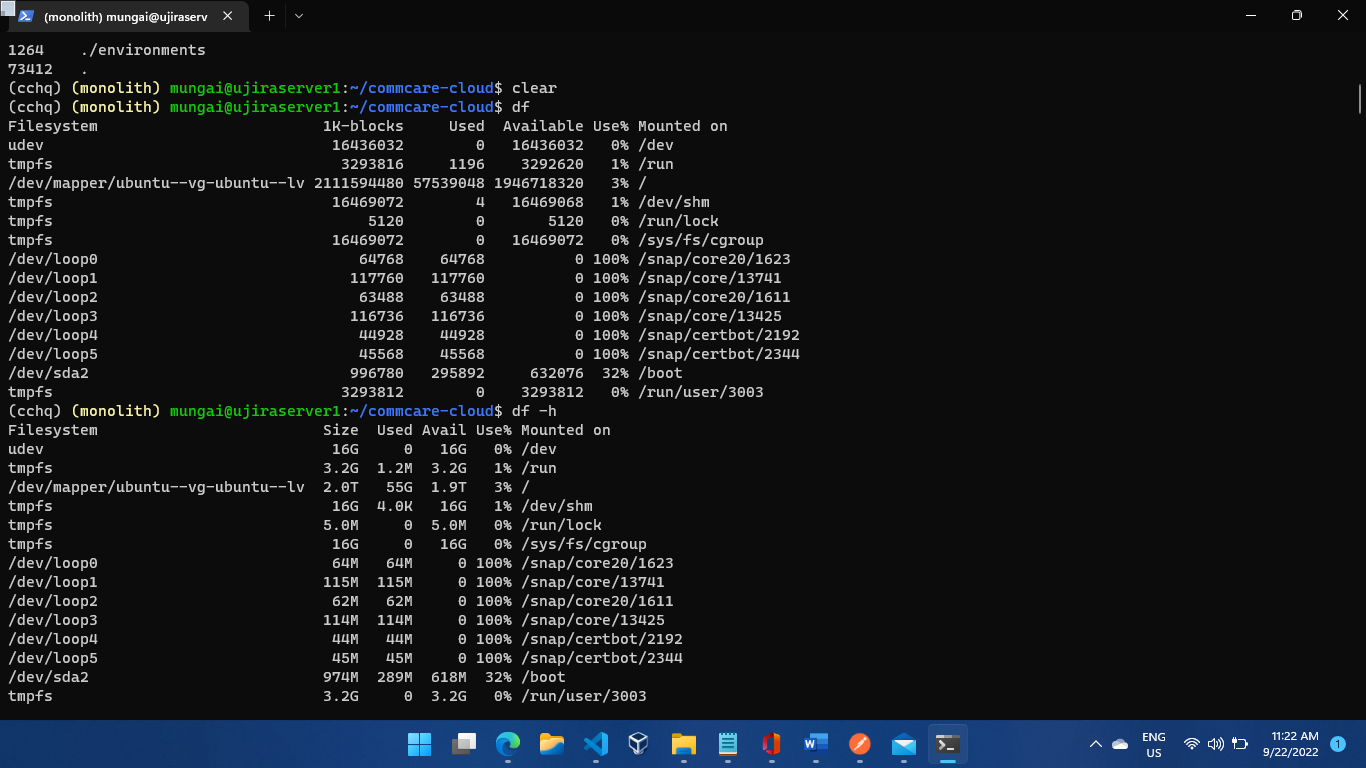
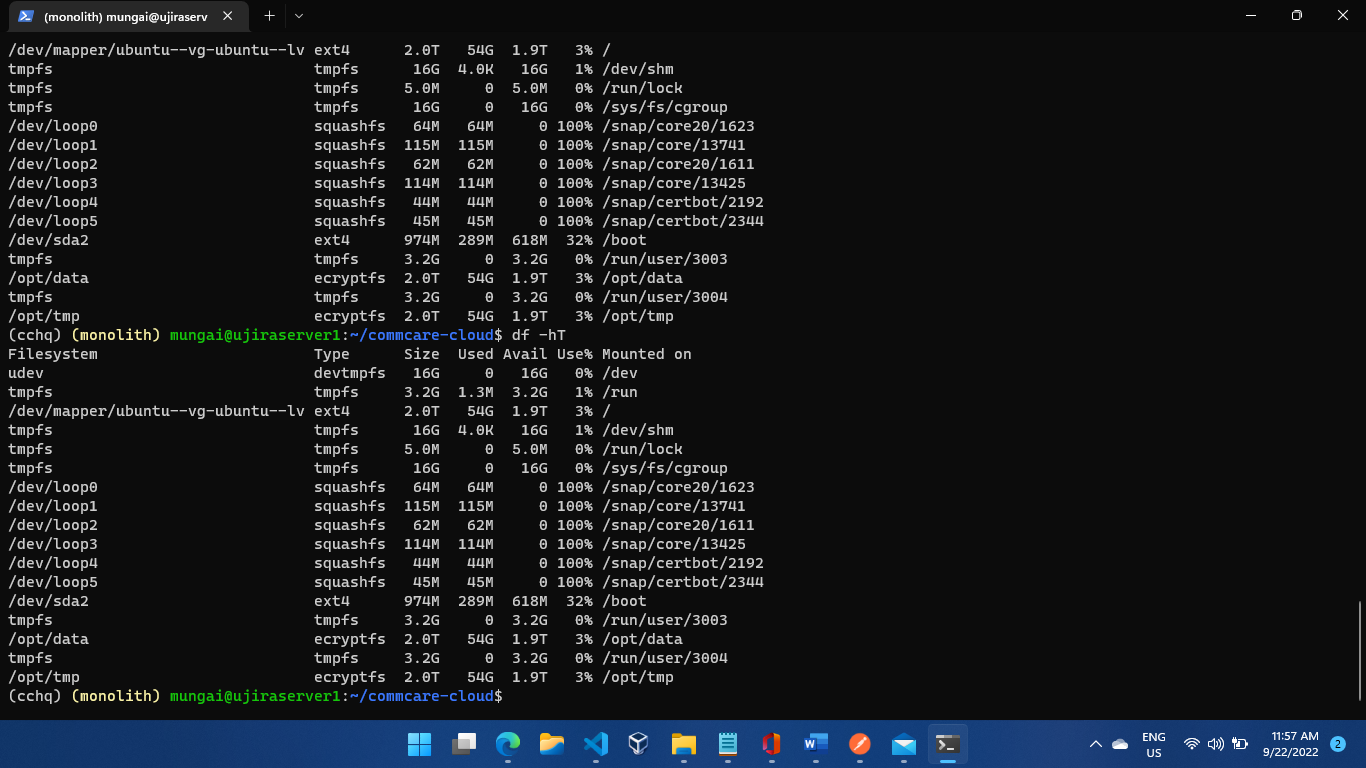
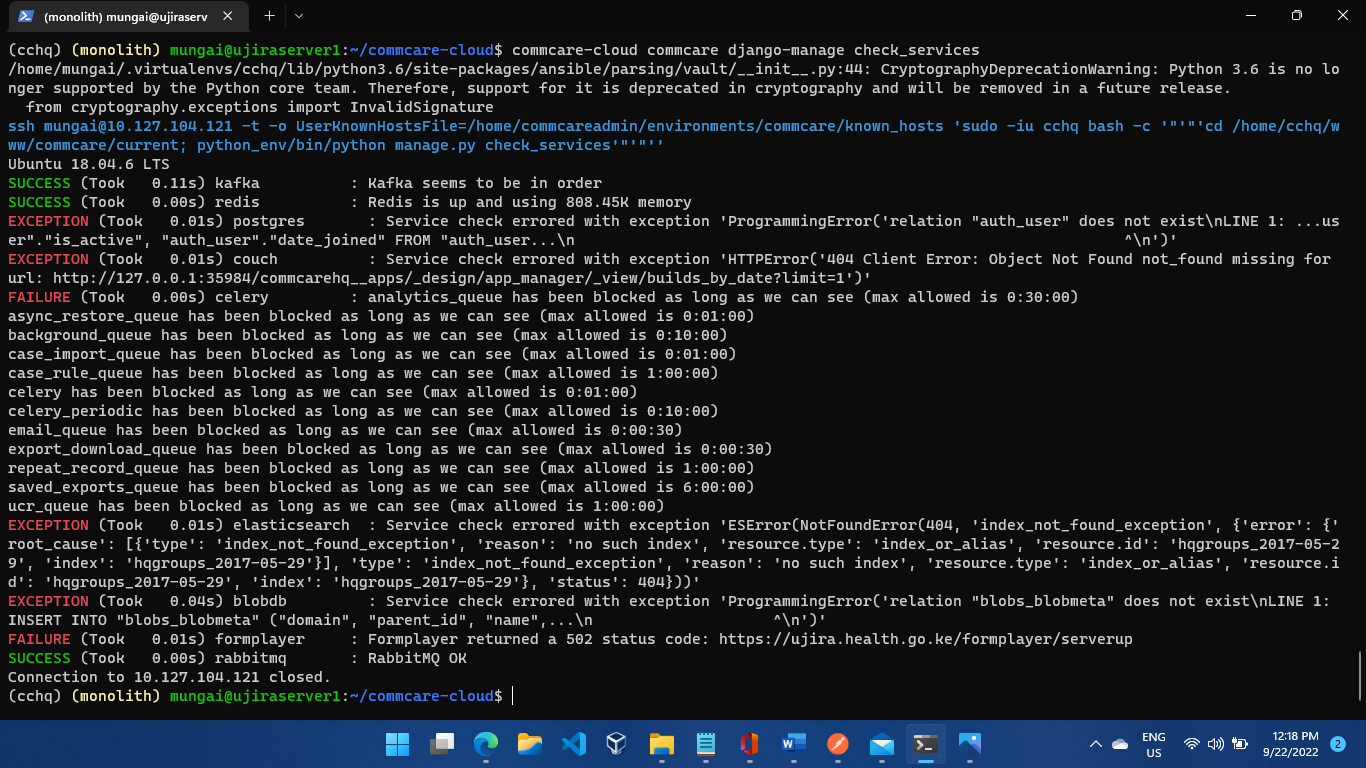
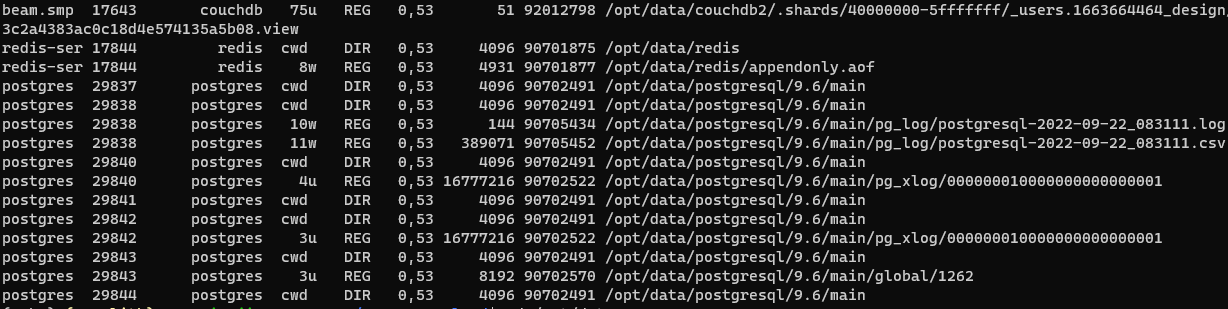
However, when I list the contents of the /opt/data directory it shows an empty directory. I can note from the screenshots that the /opt/data has some 54GB of data that seems to be inaccessible by the Ubuntu OS.
Question:
What could have gone wrong in the reboot sequence of commcare that has caused this inaccessiblity?
Is there a way to resolve this issue?
Note:
This is the response when i run the command: -
The "54GB on an empty volume" does sound curious if it is indeed empty. Maybe there are hidden files? You could verify this by running:
ls -alh /opt/data
Anyhow, the things that are expected to be in that volume are not hidden, so that seems like the real problem here. I'm curious what (and how) got mounted at /opt/data. What do you get when you execute (on the system):
Hmm, that looks normal. I was worried that somehow /opt/data got mounted twice (as in, an empty volume got mounted overtop the correct one), but that doesn't look like what's happening here.
Perhaps check the permissions of the /opt and /opt/data directories. Maybe something is locked down in a way that non-root users cannot list the directory? Try:
ls -ld /opt /opt/data
For example, when I run this on a working CommCareHQ monolith, I get this:
By default, after-reboot will mount an encrypted (ecryptfs) filesystem on /opt/data. It looks like in this case you already had data at /opt/data that the encrypted filesystem was mounted on top of, leaving it inaccessible. The easiest short term fix is to unmount the encrypted filesystem. umount /opt/data should work, I believe.
This does likely mean that the data on that server is not encrypted, unless you are using another encryption mechanism (such as an encrypted block device in aws). If you expect this data to be encrypted, you may want to copy it out of /opt/data to another location, remount the encrypted filesystem (with after-reboot) and copy it back onto the encrypted filesystem. Otherwise, you should be able to prevent after-reboot from mounting that filesystem by changing the setting root_encryption_mode to something other than ecryptfs in your environment public yaml file.
There might be other/unwanted processes making the server busy.
to see the detail you better observe the top processes running on the server: using top/htop. And for disks you can look the top disk consumming tasks by iotop command.
sudo iotop --only -d 2 to display top disk operation; refreshed every 2 seconds
Cal's suggestion seems to be the correct analysis. This is the likely chain of events that happened to get you where you are now:
The instance was rebooted.
When CommCare HQ started up, services were running using /opt/data which is just a subdirectory of your root volume (/dev/mapper/ubuntu--vg-ubuntu-lv mounted on /)
The after-reboot command was executed.
This mounted an encrypted volume on top of/opt/data, effectively obscuring the contents of the underlying /opt/data.
The reason you see the "expected file paths" when running the lsof command is because all of those file handles were opened prior to the encrypted volume being mounted overtop, and so all of those open files are still valid for the running processes that opened them. The services are still likely failing because they cannot open new files at those locations because they are now obscured by the encrypted volume mount.
There is only one way to recover from this: you must stop all running services that are attempting to use any files located in /opt/data because the umount command will fail until you do so. The easiest way to accomplish this is to completely stop the entire CommCare HQ application stack. Once all services are down, your umount command should be able to succeed. Alternatively, you could just reboot the instance and change your configuration to not use an encrypted FS (as Cal recommended) before running after-reboot again.
Is there a chain of commands that i can run to achieve this?
Yes, you can run the command commcare-cloud <env> service <service> stop for each service in the stack (docs here):
commcare-cloud <env> service webworker stop
commcare-cloud <env> service pillowtop stop
commcare-cloud <env> service celery stop
# etc, etc ...
You can also provide multiple services with one command. Something like the following should stop them all. However, your stack might not be running all of these services (I just copied these from the command help doc), so running the command below may complain about some services not running.
If you're unable to get the umount command to succeed, I would recommend updating your env config (to disable disk encryption, as Cal recommended) and rebooting the entire system. This is probably an easier route, and doing so will verify that your configuration is reboot-safe.
Update: it has been brought to my attention that there is a downtime command that will stop all services in an HQ environment (thanks @schauhan).
Stop all services: commcare-cloud <env> downtime start
Start them again: commcare-cloud <env> downtime end
Performing a reboot might still be the most "robust" solution, but the downtime command should be much easier than stopping each service individually.