We have a production server that is down after a reboot.
There appears to be an issue starting PostgreSQL with the after-reboot script.
We receive the following error:
RUNNING HANDLER [postgresql_base : Start postgres] ************************************************************************************************************
fatal: [10.1.0.4]: FAILED! => {"changed": false, "msg": "Unable to start service postgresql@10-main: Assertion failed on job for postgresql@10-main.service.\n"}
The scripts appear to be incorrectly assuming we're running PostgreSQL 10 when in fact it looks like we're on 9.6
Ahh, that might be the wrong place to look (looks like that's been at 10 for quite some time). I'm looking into where/how you specify version 9.6 for your stack.
Hey Joel, the last update (commcare-cloud and commcareHQ) was performed recently on 28 February 2022.
My src/commcare_cloud/ansible/roles/postgresql_base/defaults/main.yml does indeed specify PostgreSQL version 10
At what point was PostgreSQL upgraded to version 10 - was that a manual step that may have been missed somewhere down the line?
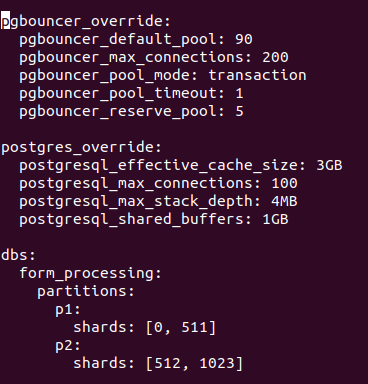
Ok, for sanity check, can you check if your commcare-cloud environment's 'postgresql.yml' file, specifically for the 'postgresql_version' under the 'postgres_override' section. I'm specifically interested if it's missing, or if it's there, what version is specified. For example, this env currently sets 9.6 explicitly: commcare-cloud/environments/production/postgresql.yml at master · dimagi/commcare-cloud · GitHub
Edit: 'postgres_override', not 'postgresql_overrides'
At what point was PostgreSQL upgraded to version 10
It wasn't, that was my oversight. I think that file just specifies the "default value", an env file (see previous post) can override it. But I'm wondering if this is related to your problem (as in, maybe your env file isn't overriding it?).
Ok, that might be the problem. Let me dig into when the "default" got changed to 10, because if that's causing your problem, then there probably should have been a changelog step for that.
I'm not sure how comfortable you are with "poking" in your env file, but you could add that override to see if it solves your problem:
We've identified the source of the postgres version problem. For any other community members who find this thread before a fix is deployed, the way to resolve this issue immediately is by updating your env's postgresql.yml file as I outlined above (quoted here for clarity).
(cchq) ccc@monolith:~/commcare-cloud$ sudo systemctl status zookeeper-server
[sudo] password for ccc:
Unit zookeeper-server.service could not be found.
Going by your systemd output, it doesn't appear that there is a zookeeper-server service unit on your system. I'm not 100% sure if a monolith needs zookeeper or not... I'd need to dig into the commcare-cloud repo a little more to determine this. For completeness, I'd have you try:
sudo systemctl daemon-reload
sudo systemctl status zookeeper-server
If that still results in the "Unit ... could not be found" error, then the next thing I would want to figure out is:
Does your monolith need zookeeper?
Yes: why is it missing?
No: why is the update check failing in its absence?
Unfortunately I have to drop offline now, I'll check back later this weekend to see if you made any progress.
(cchq) ccc@monolith:~/commcare-cloud$ sudo systemctl daemon-reload
[sudo] password for ccc:
(cchq) ccc@monolith:~/commcare-cloud$ sudo systemctl status zookeeper-server
Unit zookeeper-server.service could not be found.
It does indeed look like it's missing. To be honest, I'm not familiar with it on any of our installs.
Thanks a ton for the assistance thus far. I will report back on one of the other servers ASAP.
A quick update... I disabled the zookeeper reload after_reboot and got the server up except for celery. Celery is has been blocked and restarting it doesn't appear to get anything going. We are on a build from 28 Feb. I'll start a separate thread about the Celery issue but am happy to assist in troubleshooting and resolving this issue.
Thanks