Hi all,
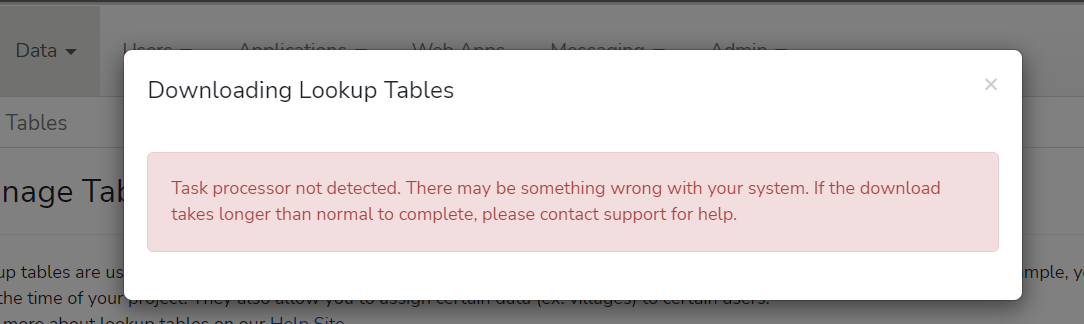
We have a local server instance running but every time we try to download the organisation structure, celery stops running and we get the error below.
The fact that this is happening for locations and mobile workers makes me suspect that maybe the environment is running out of RAM as it prepares the download file.
I would recommend using Datadog or Prometheus for monitoring resources, if you aren't already.
If you are running HQ in a monolith environment, even just running htop in a terminal will let you keep an eye on RAM usage when trying to download locations or mobile workers.
They have Prometheus on their server but we used htop and Celery seems to be taking up 99% of their memory. Is this normal?
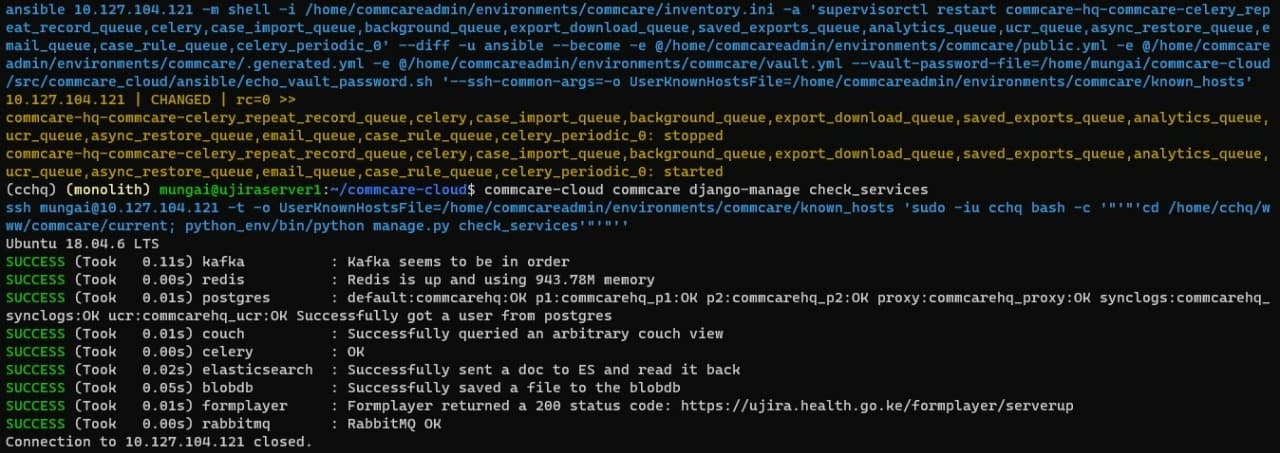
After restarting celery a few times, we were finally able to make uploads but mow celery_periodic is delayed by 1 day so we're trying to firefight that. Restarting it isn't doing anything even though the restart command runs successfully.
Yes, if it's behind, that's pretty normal. It takes some time to clear them. There is a way to flush the heartbeat queue items to help clear the queue - I think that's in the firefighting manual.
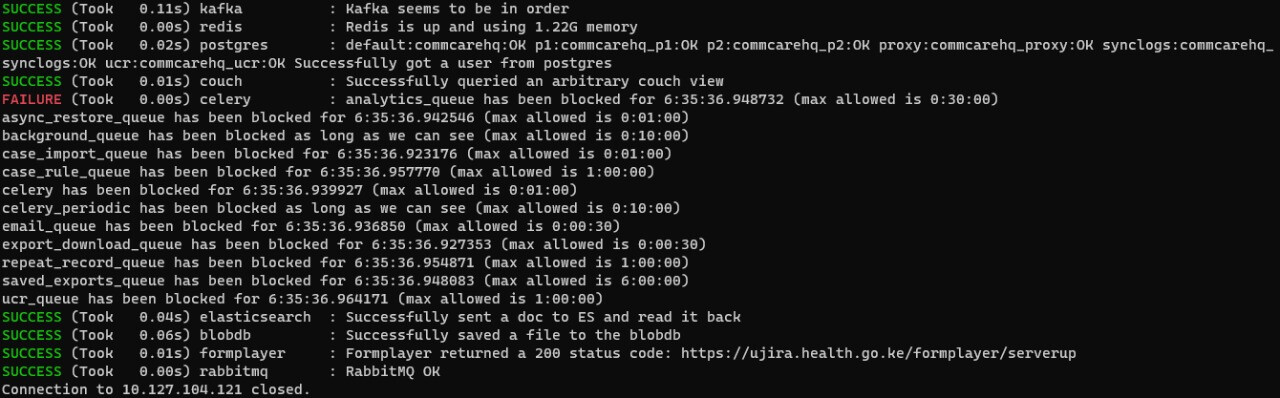
The key is to do a check_services and take note of the time that the queues have been stalled then in a minute try it again and see if that period has dropped or gone up. If it's dropped, then it's processing. The celery logs will also allude to that.
So our Celery is still crashing and giving us the error below. We've tried to restart the queues as well as monitoring Flower but still can't figure out how to fix this permanently. Any advice? Thanks!
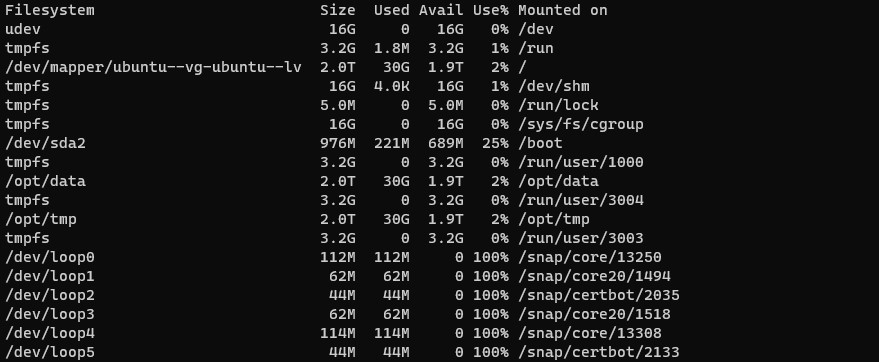
How much free space is available on the server? What is the output of df -h
How much RAM is available? What is the output of free -h
What does your celery log look like after restarting it? Open two ssh sessions and in one do a tail of the celery log while running cchq monolith service celery restart
Inspect the output.
We had a similar issue caused by the corehq.apps.data_analytics.tasks.build_last_month_MALT task. I followed the firefighting guide and discovered it when I looked at active tasks
I then discovered the (old) MALT task which I revoked.
I hope this helps!
This is actually the task that's giving us problems Ed ( corehq.apps.data_analytics.tasks.build_last_month_MALT task)! I saw it yesterday. Let's try to revoke it.
@clara@EzraMungai those specs look fine. I don't see any memory issues, though our production servers generally have 56Gb RAM or more. Requirements would depend on your usage and number of users submitting data etc. It's not an easy calculation unfortunately. There has apparently been an update to the MALT task in a newer build, so deploying the latest might solve the issue. See here:
Clearing the MALT task in the mean time as per the firefighting instructions may sort it out until the next monthly run.